まず、エクセルでデータを作成します(エディタでも十分です。一致させたい単語を列記するだけです)。
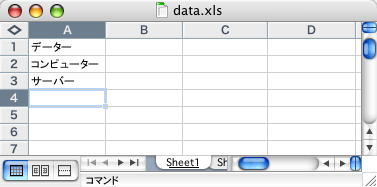
最初の列が置き換える前の文字、次が置き換える文字になります。次に「テキスト(タブ区切り)形式」で保存します。
変換したファイルは日本語フォルダ名やボリュームを含まないフォルダにコピーまたは移動させます。サンプルではMacintosh HDボリューム内にdata.txtというファイル名で用意してあります。
ファイルから読み込みを行い単語を配列に入れます。読み込むファイルを上から2行目で指定します。File()の中で読み込むファイルのパスを指定します。ここではMacintosh用のパス表記にしていますが、安全のため使用しているOS固有のパス指定にしてください。ファイルからreadln()で一行読み込みタブコードで分割します。分割したデータは配列に入りますので、その配列を用意した単語の配列に入れます。
選択されたテキストフレームのcontentsにある文字列を正規表現を使って一致するかどうか調べ一致した場合に警告を出すようにします。これはmatch()を使えば簡単にできます。この作業を選択されたテキストフレーム数と単語の数だけ繰り返します。
■ソースコード
function checker()
{
// 単語読み込み
srcText = new Array();
repText = new Array();
count = 0;
while(!fileObj.eof)
{
text = fileObj.readln(); // 1行読み込む
txtItem = text.split(TAB); // タブコードで分割
srcText[count] = txtItem[0]; // 元の文字
repText[count] = txtItem[1]; // 置換する文字
count = count + 1;
}
// 検索・置換処理
pageObj = app.activeDocument.selection;
for (i=0; i<pageObj.length; i++)
{
for (j=0; j<count; j++)
{
regObj = new RegExp(srcText[j],"g");
if (pageObj[i].contents.match(regObj))
{
alert("おかしな単語が含まれています");
return;
}
}
}
}
TAB = String.fromCharCode(9); // タブコード
fileObj = new File("Macintosh HD:data.txt");
flag = fileObj.open("r");
if (flag)
{
checker();
}
■ポイント
読み込むファイルの日本語文字コードはUnicode (UCS-2)にしてください。つまり、一度エクセルからタブ区切りテキストで書き出した後に、JEDITなどで文字コードを変換するようにした方が安全です。また、タブ区切りテキストではデータの前後に"(ダブルクォーテーション)が付加されることがありますが、このサンプルではダブルクォーテーションを削除する処理は行っていません。
